Mining Twitter¶
Twitter implements OAuth 1.0A as its standard authentication mechanism, and in order to use it to make requests to Twitter's API, you'll need to go to https://dev.twitter.com/apps and create a sample application. There are four primary identifiers you'll need to note for an OAuth 1.0A workflow: consumer key, consumer secret, access token, and access token secret. Note that you will need an ordinary Twitter account in order to login, create an app, and get these credentials.
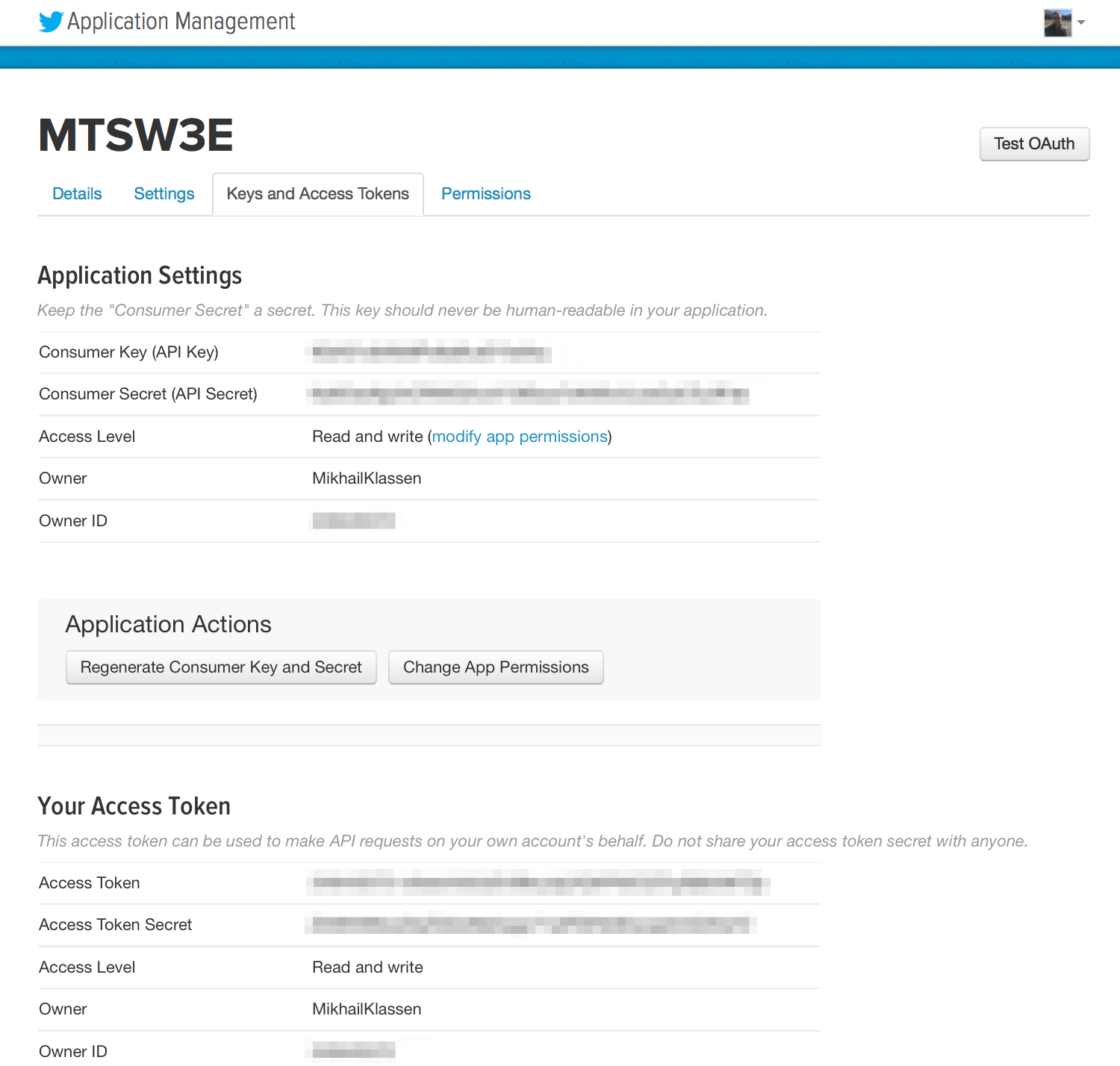
If you are taking advantage of the virtual machine experience for this chapter that is powered by Vagrant, you should just be able to execute the code in this notebook without any worries whatsoever about installing dependencies. If you are running the code from your own development envioronment, however, be advised that these examples in this chapter take advantage of a Python package called twitter to make API calls. You can install this package in a terminal with pip with the command pip install twitter, preferably from within a Python virtual environment.
Once installed, you should be able to open up a Python interpreter (or better yet, your IPython interpreter) and get rolling.
Authorizing an application to access Twitter account data¶
import twitter
# Go to http://dev.twitter.com/apps/new to create an app and get values
# for these credentials, which you'll need to provide in place of these
# empty string values that are defined as placeholders.
# See https://developer.twitter.com/en/docs/basics/authentication/overview/oauth
# for more information on Twitter's OAuth implementation.
CONSUMER_KEY = ''
CONSUMER_SECRET = ''
OAUTH_TOKEN = ''
OAUTH_TOKEN_SECRET = ''
auth = twitter.oauth.OAuth(OAUTH_TOKEN, OAUTH_TOKEN_SECRET,
CONSUMER_KEY, CONSUMER_SECRET)
twitter_api = twitter.Twitter(auth=auth)
# Nothing to see by displaying twitter_api except that it's now a
# defined variable
print(twitter_api)
Retrieving trends¶
# The Yahoo! Where On Earth ID for the entire world is 1.
# See https://dev.twitter.com/docs/api/1.1/get/trends/place and
# http://developer.yahoo.com/geo/geoplanet/
WORLD_WOE_ID = 1
US_WOE_ID = 23424977
# Prefix ID with the underscore for query string parameterization.
# Without the underscore, the twitter package appends the ID value
# to the URL itself as a special case keyword argument.
world_trends = twitter_api.trends.place(_id=WORLD_WOE_ID)
us_trends = twitter_api.trends.place(_id=US_WOE_ID)
print(world_trends)
print()
print(us_trends)
for trend in world_trends[0]['trends']:
print(trend['name'])
for trend in us_trends[0]['trends']:
print(trend['name'])
world_trends_set = set([trend['name']
for trend in world_trends[0]['trends']])
us_trends_set = set([trend['name']
for trend in us_trends[0]['trends']])
common_trends = world_trends_set.intersection(us_trends_set)
print(common_trends)
Anatomy of a Tweet¶
import json
# Set this variable to a trending topic,
# or anything else for that matter. The example query below
# was a trending topic when this content was being developed
# and is used throughout the remainder of this chapter.
q = '#MothersDay'
count = 100
# Import unquote to prevent url encoding errors in next_results
from urllib.parse import unquote
# See https://dev.twitter.com/rest/reference/get/search/tweets
search_results = twitter_api.search.tweets(q=q, count=count)
statuses = search_results['statuses']
# Iterate through 5 more batches of results by following the cursor
for _ in range(5):
print('Length of statuses', len(statuses))
try:
next_results = search_results['search_metadata']['next_results']
except KeyError as e: # No more results when next_results doesn't exist
break
# Create a dictionary from next_results, which has the following form:
# ?max_id=847960489447628799&q=%23RIPSelena&count=100&include_entities=1
kwargs = dict([ kv.split('=') for kv in unquote(next_results[1:]).split("&") ])
search_results = twitter_api.search.tweets(**kwargs)
statuses += search_results['statuses']
# Show one sample search result by slicing the list...
print(json.dumps(statuses[0], indent=1))
for i in range(10):
print()
print(statuses[i]['text'])
print('Favorites: ', statuses[i]['favorite_count'])
print('Retweets: ', statuses[i]['retweet_count'])
Extracting text, screen names, and hashtags from tweets¶
status_texts = [ status['text']
for status in statuses ]
screen_names = [ user_mention['screen_name']
for status in statuses
for user_mention in status['entities']['user_mentions'] ]
hashtags = [ hashtag['text']
for status in statuses
for hashtag in status['entities']['hashtags'] ]
# Compute a collection of all words from all tweets
words = [ w
for t in status_texts
for w in t.split() ]
# Explore the first 5 items for each...
print(json.dumps(status_texts[0:5], indent=1))
print(json.dumps(screen_names[0:5], indent=1) )
print(json.dumps(hashtags[0:5], indent=1))
print(json.dumps(words[0:5], indent=1))
Creating a basic frequency distribution from the words in tweets¶
from collections import Counter
for item in [words, screen_names, hashtags]:
c = Counter(item)
print(c.most_common()[:10]) # top 10
print()
Using prettytable to display tuples in a nice tabular format¶
from prettytable import PrettyTable
for label, data in (('Word', words),
('Screen Name', screen_names),
('Hashtag', hashtags)):
pt = PrettyTable(field_names=[label, 'Count'])
c = Counter(data)
[ pt.add_row(kv) for kv in c.most_common()[:10] ]
pt.align[label], pt.align['Count'] = 'l', 'r' # Set column alignment
print(pt)
Calculating lexical diversity for tweets¶
# A function for computing lexical diversity
def lexical_diversity(tokens):
return len(set(tokens))/len(tokens)
# A function for computing the average number of words per tweet
def average_words(statuses):
total_words = sum([ len(s.split()) for s in statuses ])
return total_words/len(statuses)
print(lexical_diversity(words))
print(lexical_diversity(screen_names))
print(lexical_diversity(hashtags))
print(average_words(status_texts))
Finding the most popular retweets¶
retweets = [
# Store out a tuple of these three values ...
(status['retweet_count'],
status['retweeted_status']['user']['screen_name'],
status['retweeted_status']['id'],
status['text'])
# ... for each status ...
for status in statuses
# ... so long as the status meets this condition.
if 'retweeted_status' in status.keys()
]
# Slice off the first 5 from the sorted results and display each item in the tuple
pt = PrettyTable(field_names=['Count', 'Screen Name', 'Tweet ID', 'Text'])
[ pt.add_row(row) for row in sorted(retweets, reverse=True)[:5] ]
pt.max_width['Text'] = 50
pt.align= 'l'
print(pt)
Looking up users who have retweeted a status¶
# Get the original tweet id for a tweet from its retweeted_status node
# and insert it here
_retweets = twitter_api.statuses.retweets(id=862359093398261760)
print([r['user']['screen_name'] for r in _retweets])
Plotting frequencies of words¶
import matplotlib.pyplot as plt
%matplotlib inline
word_counts = sorted(Counter(words).values(), reverse=True)
plt.loglog(word_counts)
plt.ylabel("Freq")
plt.xlabel("Word Rank")
Generating histograms of words, screen names, and hashtags¶
for label, data in (('Words', words),
('Screen Names', screen_names),
('Hashtags', hashtags)):
# Build a frequency map for each set of data
# and plot the values
c = Counter(data)
plt.hist(list(c.values()))
# Add a title and y-label ...
plt.title(label)
plt.ylabel("Number of items in bin")
plt.xlabel("Bins (number of times an item appeared)")
# ... and display as a new figure
plt.figure()
Generating a histogram of retweet counts¶
# Using underscores while unpacking values in
# a tuple is idiomatic for discarding them
counts = [count for count, _, _, _ in retweets]
plt.hist(counts)
plt.title('Retweets')
plt.xlabel('Bins (number of times retweeted)')
plt.ylabel('Number of tweets in bin')
Sentiment Analysis¶
# pip install nltk
import nltk
nltk.download('vader_lexicon')
import numpy as np
from nltk.sentiment.vader import SentimentIntensityAnalyzer
twitter_stream = twitter.TwitterStream(auth=auth)
iterator = twitter_stream.statuses.sample()
tweets = []
for tweet in iterator:
try:
if tweet['lang'] == 'en':
tweets.append(tweet)
except:
pass
if len(tweets) == 100:
break
analyzer = SentimentIntensityAnalyzer()
analyzer.polarity_scores('Hello')
analyzer.polarity_scores('I really enjoy this video series.')
analyzer.polarity_scores('I REALLY enjoy this video series.')
analyzer.polarity_scores('I REALLY enjoy this video series!!!')
analyzer.polarity_scores('I REALLY did not enjoy this video series!!!')
scores = np.zeros(len(tweets))
for i, t in enumerate(tweets):
# Extract the text portion of the tweet
text = t['text']
# Measure the polarity of the tweet
polarity = analyzer.polarity_scores(text)
# Store the normalized, weighted composite score
scores[i] = polarity['compound']
most_positive = np.argmax(scores)
most_negative = np.argmin(scores)
print('{0:6.3f} : "{1}"'.format(scores[most_positive], tweets[most_positive]['text']))
print('{0:6.3f} : "{1}"'.format(scores[most_negative], tweets[most_negative]['text']))